Ureport报表
集成及配置
简述
报表简介
UReport2是一款基于架构在Spring之上纯Java的高性能报表引擎,通过迭代单元格可以实现任意复杂的中国式报表。 在UReport2中,提供了全新的基于网页的报表设计器,可以在Chrome、Firefox 等各种主流浏览器运行 (不支持IE)。 使用UReport2,打开浏览器即可完成各种复杂报表的设计制作。
主体功能
- UReport2支持创建数据源、添加数据集,并对数据集进行函数、表达式处理;
- UReport2支持对数据集形成可视化报表,包括饼状图、柱状图、曲线图等等
优缺点阐述
优点:
- 开源、免费,集成即可使用,可二开后商用;
- 轻量级、易集成,工程中添加依赖即可进行集成使用;
- 支持多函数处理,包括常用函数(sum、count、max、min、avg)、数学函数、字符串函数、日期函数等等;
- 支持多种图表展示,包括饼状图、柱状图、曲线图、圆环图、雷达图、散点图等等;
缺点:
- 数据集查询简易,sql拼接不友好、不直观;
- 支持数据源类型少,当前支持:mysql、SQLserver、oracle、db2等
集成及配置
目前基于原有Ureport2代码已经拆分成前后台分离模式,前后台已集成现有架构体系,针对现有我们的易企积架构体系可直接使用。
如现有项目A需增加报表服务,仅需以下几步:
- 从现有GitLab仓库中fork出Ureport项目后,取消关联关系
- 更改项目数据库、Redis配置信息,Redis配置要与网关鉴权、用户服务共用一个桶,要不然权限信息获取失败!
- 配置jenkins,发版项目。
报表基础配置
基本概念
报表计算模型
在设计器中单元格之间存在依赖关系,对于任意一个单元格都可以设置它的左父格与上父格。单元格父格是可选的,默认情况下,单元格的左父格就是其最近左边与其位于同一行的单元格;上父格则是其最近上方与其位于同一列的的单元格。如果一个单元格位于第一行,那默认它就没有上父格,同样,如果位于第一列,默认它就没有左父格。打开报表设计器,选中任意单元格,都可以在其属性面板看到它的默认上父格或左父格。
行类型
单元格栏,可针对指定单元格进行单元格样式及数据的设置,鼠标右键可设置单元格;
- 标题行
在报表计算后分页时只会出现在第一页第一行的行,如果定义了多个行为标题行类型,那么这些行将在报表运行后分页输出时第一页最前面插入标题行。需要注意的是,我们在报表中可以将位于任意位置的行定义成标题行,但报表计算分页输出时,总会将这些定义为标题行的行放在报表的第一页最前端显示; - 重复表头
与标题行不同的是,定义为重复表头行的行,在报表计算分页输出时会将定义成重复表头行的行放在每一页的前端进行显示。如果当前报表中定义的有标题行,那么对于第一页,标题前将位于最上面,其下才是重复表头行定义的行; - 重复表尾
与重复表头行类型,它也会在报表计算分页输出时放在每一页中显示,只是它会在每一页的最下端显示; - 总结行
与标题行对应,总结行会出现在报表计算后分页输出时最后一页的最下端显示。如果当前报表中定义了重复表尾行,那么在报表计算后分页输出的最后一页中总结后将位于重复表尾行下方显示。
数据集
SQL输入区同样支持表达式语法,表达式以${}进行包裹
表达式模式:
param是固定表达,表示参数。当参数为空或为null时,全查询,否则查询指定类型的表记录,主要用于后续处理数据,在设计表单时可针对当前参数设置查询条件,可以使用如下:
1 | |
这里我以一个统计阳性率的sql为例,sql信息拼接以及参数拼接如下:
注意:
报表服务因为已经集成的现有鉴权体系,所以现有userId、tenantId、orgId、orgPath信息从token中获取,如有使用数据权限等信息可直接拼接参数,不用通过报表查询参数获取即可。
1 | |
配置数据集后可预览结果查看SQL的执行结果,如果没有问题则保存后,把对应的字段直接拖拽到表格中,点击预览查看具体结果即可。
数据处理
单元格引用
在报表当中,大多数的计算都是针对单元格或与单元格有关,因为报表中单元格多数都与数据绑定,而数据往往又是多条,所以计算后的报表一个单元格会产生多个,这样对于单元格的引用就变的比较复杂。在报表设计器中,引用的目标单元格是相对当前单元格来进行计算的,引用方法就是直接在表达式里书写单元格名称,比如引用A1单元格,就直接写A1即可。

在上图当中,我们在D1单元格中输入表达式A1,这就表示,在D1单元格里填入相对当前D1单元格的A1单元格的值,运行后的效果如下:
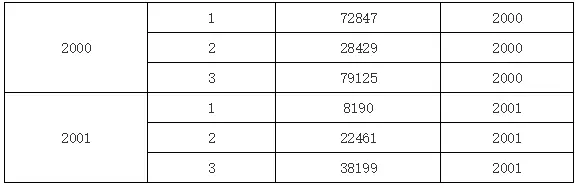
可以看到,因为D1是A1的子格,A1单元格绑定的数据就是分组结构,根据当前D1单元格的位置,就产生的上图所示的结果。如果在D1单元格中输入B1,那么运行后的效果又是下图的样子:
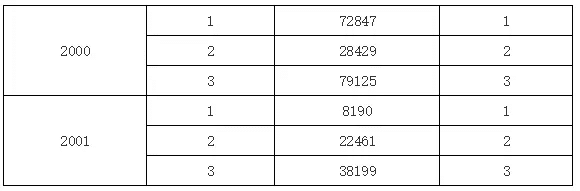
通过上面的例子我们可以看到,某个单元格的表达式引用目标单元格,首先判断的是目标单元格与其所在单元格是否位于同一行或行,如果是则直接取对应行或列上目标单元格的值。如果当前单元格与目标单元格不在同一行或列,那情况又不一样了,我们来看下一个例子。

在上面的例子中,我们在C2单元格的表达式中输入B1,表示取B1单元格的值,但B1单元格又和C2不在同一行或列上,同时B1单元格展开后会有多个值,但B1单元格和C2单元格都拥有一个共同的父格或间接父格A1(C2单元格的左父格是B2,而B2单元格的左父格又是A1,所以A1是C2单元格的间接左父格),所以它会取他们共同父格A1下所有B1的值,运行结果如下图所示:
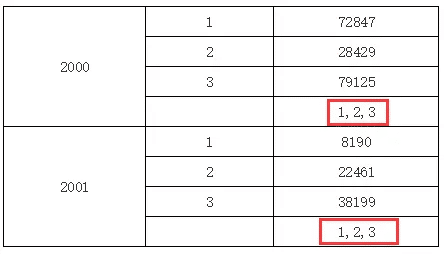
针对上面的例子,如果我们在上面的单元格中输入C1,那结果又不一样;因为C1是C2的上父格,所以将直接取与其位于同一列的上父格单元格的值,运行效果如下图所示:
再看下面的报表示例:

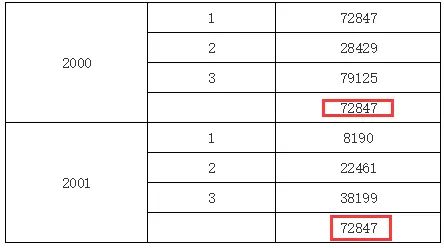
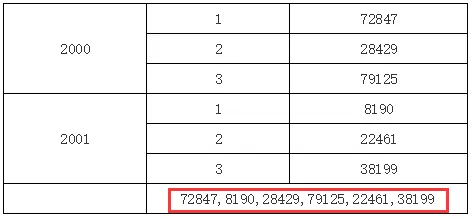
在上面的例子中,B2单元格表达里输入C1,因为B2和C2既不在同一行或列,也没有共同的父格,所以B2中将取到所有的C1单元格的值,如下图所示:
单元格坐标
为了实现更为复杂的单元格引用,设计器引用了单元格坐标的概念。单元格坐标,也是相对于当前单元格来进行计算的,同样遵循上面的介绍的优先取同行、同列或共同父格的原则,一个标准的单元格坐标格式如下:
单元格坐标格式:单元格名称[Li:li,Li-1:li-1,…;Ti:ti,Ti-1:ti-1…]{条件…}
L表示左父格,l表示左父格展示后的序号,序号为负值,表示向上位移;T表示上父格,t表示上父格展开后的序号,序号为负值,表示相对于当前单元格向上位移,正值则表示向下位移,如果只有左父格,那么直接写L部分即可;如果只是上父格,那么前面需要加上“;”号,然后写T部分,后面的大括号中是条件部分,多个条件之间用and/or连接,表示对通过坐标取到的单元格进行条件过滤(如果取到多个单元格的话),条件部分是可选的,相关示例如下:
| 单元格坐标示例 | 描述 |
|---|---|
| C1[A1:2,B1:1] | 在找C1时先找单元格A1展开后的第2格;再找第二个A1下的B1单元格展开后的第一个单元格,然后再找这个B1单元格对应的C1单元格 |
| C2[A1:2,B1:2;C1:3] | 在找C2时,先找A1单元格展开后的第二格,再找第二个A1单元格下B2单元格展开后的第二格,再根据第二个展开的B2单元格找其下名为C2单元格的左子格;然后再找到C1单元格展开后的第三格,再看其下的C2单元格,取C2单元格的交集 |
| C2[A1:2,B2:2]{C2>1000} | 表示取A2单元格展开后的第二格,再取其下B2单元格展开后第二格,再取B2下所有的C2单元格,最后再对取到的C2单元格进行条件过滤,只取出C2单元格值大于1000的所有C2单元格。 |
| C2[A1:2,B2:2]{C2>1000 and C2<10000} | 表示取A2单元格展开后的第二格,再取其下B2单元格展开后第二格,再取B2下所有的C2单元格,最后再对取到的C2单元格进行条件过滤,只取出C2单元格值大于1000且小于10000的所有C2单元格的值。 |
我们来看一个具体的示例,报表模版如下:
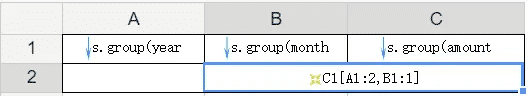
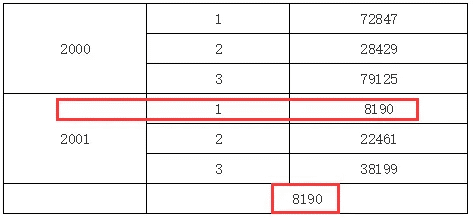
在上面的报表模版中,在B2单元格表达式里,我们输入了C1[A1:2,B1:1],这就表示取A1单元格展开后第二格下B1单元格展开后第一格下对应的C1单元格的值,所以运行后我们可以看到如下图所示效果:
我们首先来看一个环比的例子。
环比
报表模版如下图所示:

在上面的报表模版中,D2 单元格中的表达式为 C2 - C2[A2:-1] ,这就表示在D2单元格中首先取到 C2 单元格的值, 因为 C2 单元格与 D2 位于同一行,所以可以直接取到,且只有一个;下一个C2采用了坐标A2:-1,那就表示取相对于当前单元格的 A2 单元格上一格(负值表示向上位移)的A2单元格所对应的 C2 单元格,运行后的效果如下图所示:
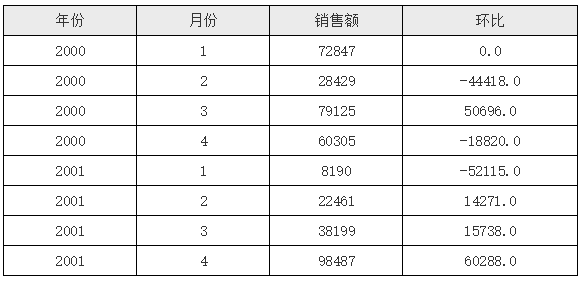
从运行结果中可以看到,第一行环比的值为0,这是因为对于第一行的 D2 单元格来说,其上一行其实是不存在的,所以 UReport2 默认就取了第一个 C2 单元格的值,所以两个值减下来就是0。
下一个例子我们来看看同比。
同比
报表模版如下图所示:

在上面的模版当中,D2 单元格中首先取到与其同行的 C2 单元格的值,然后利用单元格坐格,先取到当前 D2 单元格所在行的 A2 单元格的上一条 A2 单元格记录(-1表示坐标上移),然后再取这个 A2 下对应的 C2 单元格,但由于其下 C2 单元格还是有多个,所以这里加了个条件B2==$B2,这里的第一个 B2 表示当前单元格所在行对应的 B2 的值,$B2 表示坐标定位后 C2 单元格对应的 B2 单元格的值,条件就是他们俩要相等,实际上就是月份相等,这样就达到了我们要实现的同比的目的,运行后的效果如下:
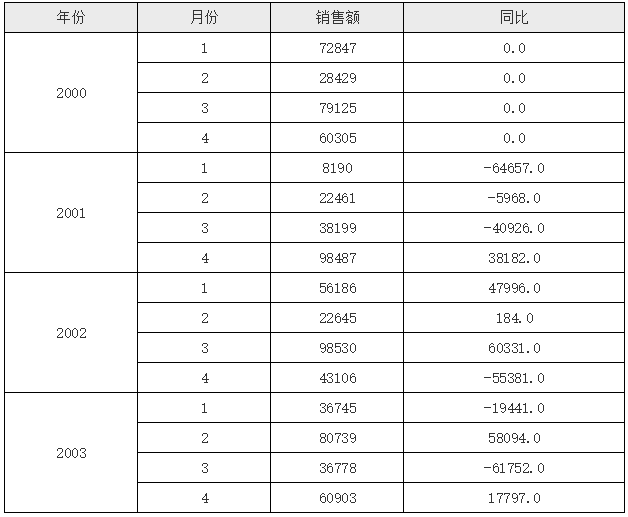
关于$B2在UReport2当中,在单元格名称前加$符号,表示取相对于目标单元格的单元格的值,多用在条件比较当中,比如上面的C2[A2:-1]{B2==$B2},这里的$B2就是指取到的C2单元格对应的B2单元格的值。
在上面的例子中,第一个分组2000下,所有的同比值都为0,这是因为这个分组下不存在 A2:-1 这个坐标,没法上移,所以系统默认取了当前记录自身,所以计算后的值都是0。如果我们不希望显示0,那么可以加个 if 条件判断表达式,如果当前位于第一个分组,就输出空字符串,否则输出实际计算后的值,修改后的报表模版如下图所示:

D2 单元格对应的表达内容如下图所示:

运行后的效果如下图所示:
在上面的例子中,我们使用了 if 判断表达式,当然你也可以换成三元表达式判断或 case 判断,在这个 if 判断中,首先我们判断的是 &A2==1 是否成立,这里的 &A2 指的是相对于当前单元格 A2 单元格展开后的序号,在 UReport2 中,可以采用“&单元格名称”的方式标记某个单元格展开后的序号,需要注意的是,使用“&单元格名称”来标记目标单元格展开后的序号时,当前单元格必须是目标单元格的子格或间接子格;比如,在上面的例子中,使用 &A2 的单元格是 D2,D2 是 A2 单元格的间接子格,这样就可以正确取到 A2 展开后的序号值。
关于&标记的使用
在使用“&单元格名称”来标记目标单元格展开后的序号时,除上需要注意上面描述的内容外,还需要注意,取序号将以他们共同的父格为基准,如果他们有共同的父格,那么将以这个父格里目标单元格的数量来进行序号编排,这在之前视频教程介绍报表计算模型中,实现明细型主从报表,对从表数据进行编号时就有体现。
逐层累加
报表模版如下图所示:

D2 单元格对应的表达式如下:

在上面的表达式中,我们采用了 if 判断(同样你可以换成三元判断或 case 判断),当相对当前单元格A2展开后的序号为1时,那么直接取当前行的 C2 单元格值,否则就拿当前行的 C2 单元格值加上,上一行D2 单元格值,这样就实现了逐层累加的需求,运行后的效果如下:
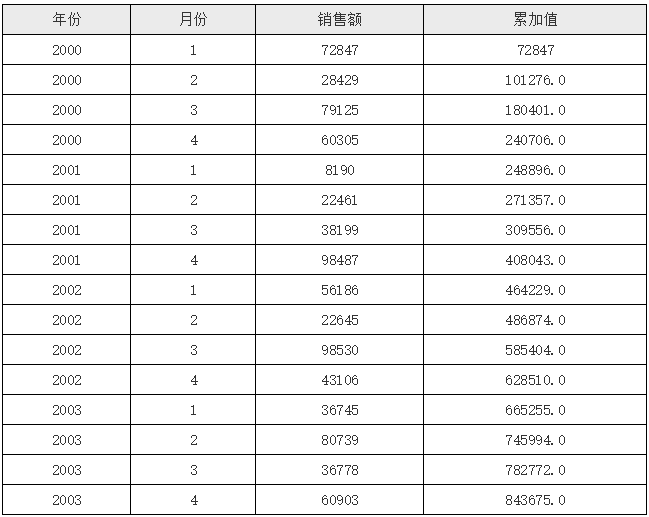
回到报表设计界面,查看表格具体参数配置,当前所有字段默认聚合方式均为:分组;
| 聚合方式 | 用途 |
|---|---|
| 列表(select) | 对数据不作处理完整展示 |
| 分组(group) | 将数据相同的作为一组进行展示 |
| 自定义分组 | 对数据自定义条件并进行分组,比如reader_number大于1000 |
| 汇总(sum) | 针对数值型字段数据,统计该字段值相加的和,比如transfer_task记录中reader_number的和 |
| 统计数量(count) | 针对数值型字段数据,统计所有记录中记录的条数,比如139条transfer_task记录 |
| 最大值(max) | 针对数值型字段数据,展示当前记录中该字段值最大的那条记录 |
| 最小值(min) | 针对数值型字段数据,展示当前记录中该字段值最小的那条记录 |
| 平均值(avg) | 针对数值型字段数据,展示当前记录中该字段的平均值 |
图表展示
UReport2中支持10种类型的图表,分别是:饼状图、圆环图、曲线图、柱状图、水平柱状图、面积图、雷达图、极坐标图、散点图以及气泡图,选择单元格类型为图表,在下方弹出的菜单中选择目标图表类型,即可完成图表的添加工作。
选中图表所在单元格,即可在属性面板中配置图表的相关属性。在UReport2中,图表的属性有三类,分别是与数据集绑定的属性、配置XY轴的相关属性以及配置图例标题之类的属性。
对于饼状图、圆环图、雷达图、极坐标图图表来说,由于它们没有XY轴,所以在属性面板中看不到XY轴配置标签页。
在绑定数据集配置的的标签页中,可以用来配置图表要表现的具体数据,在UReport2中图表绑定的数据都来自数据源,所以在配置图表之前,我们需要准备好需要用图表展示的具体数据的数据集。
对于饼状图、圆环图、曲线图、柱状图、水平柱状图、面积图、雷达图、极坐标图几种图表来说,它们要展示数据结构一样。